How revenue decisions shape technical debt
Technical debt is a term used to describe architecture that, in hindsight, should have been built differently. You see it as brittle code, fragile workflows, and slowing delivery cycles. Yet its origins rarely sit within engineering alone. Technical debt often begins upstream, in commercial decisions that prioritise short-term revenue commitments and defer the investment required to build scalable, resilient architecture.
We don't consider debt itself to be inherently bad. When you take it deliberately, it buys time. The problem emerges when you consistently trade long-term scalability for immediate wins. Over time, those "interest payments" appear as rising operating expenditure (OpEx), missed delivery commitments, and burnt-out teams that you still have to rely on.
We like how Jason Knight characterises this challenge as "revenue debt" in his blog post 5 Different Types of Debt That Can Hinder Your Product Organisation. It reflects a dynamic we frequently encounter across maturing platforms: revenue appears strong on the surface, while operational overhead, risk exposure, and platform fragmentation accumulate beneath it.
This post examines revenue debt through an engineering leadership lens, informed by Jake's background as Hyperact’s Director of Engineering and prior roles as an Engineering Manager, Architect, Tech Lead, and Engineer, so you can map the patterns to your own context and begin to make incremental changes to regain control without halting delivery. If you’re looking for the product point of view, we’ve also written this practical guide to tech debt: The tech debt elephant: A product perspective.
When revenue decisions drive architecture
You probably recognise at least one of these patterns:
- The business reacts to the loudest or highest paying customer without a cohesive product strategy
- A legacy product continues to sustain today’s revenue model, even as it conflicts with the intended product direction
- Strategic bets, R&D initiatives, and innovation pivots proceed without a clear plan for convergence into the core architecture
Individually, each decision appears rational when you make it. Collectively, they create variability your architecture must absorb. Over time, this variability compounds, slowing delivery, increasing fragility, and elevating the cost of change.
The legacy revenue trap
Given the long tail nature of product revenue, technical architecture often persists long after the strategic product value it underpinned declines. This creates a dynamic where investment decisions favour maintenance over forward progress. "temporary-life support" mechanisms, duplicated services, partial migrations, or interim integrations become permanent fixtures, tying your future architecture to outdated patterns and consuming disproportionate operating expenditure.
The bespoke revenue model
Custom builds accelerate early revenue but fragment the architecture. Each customer-specific workflow, data shape, or integration you agree to introduces additional variation that slows delivery, increases support overhead, and complicates architectural evolution. Over time, the product becomes a collection of exceptions rather than a coherent technical design your teams can evolve.
The portfolio overreach
Funding every promising idea creates a portfolio where each initiative develops its own tech stack, data model, and delivery pipeline. This optionality mimics agility in the short term, but in practice leads to duplicated architectures, inconsistent patterns, and long-term capability dilution. Unless investment scales proportionally, fragmentation compounds faster than your organisation can manage.
The flywheel of constraint
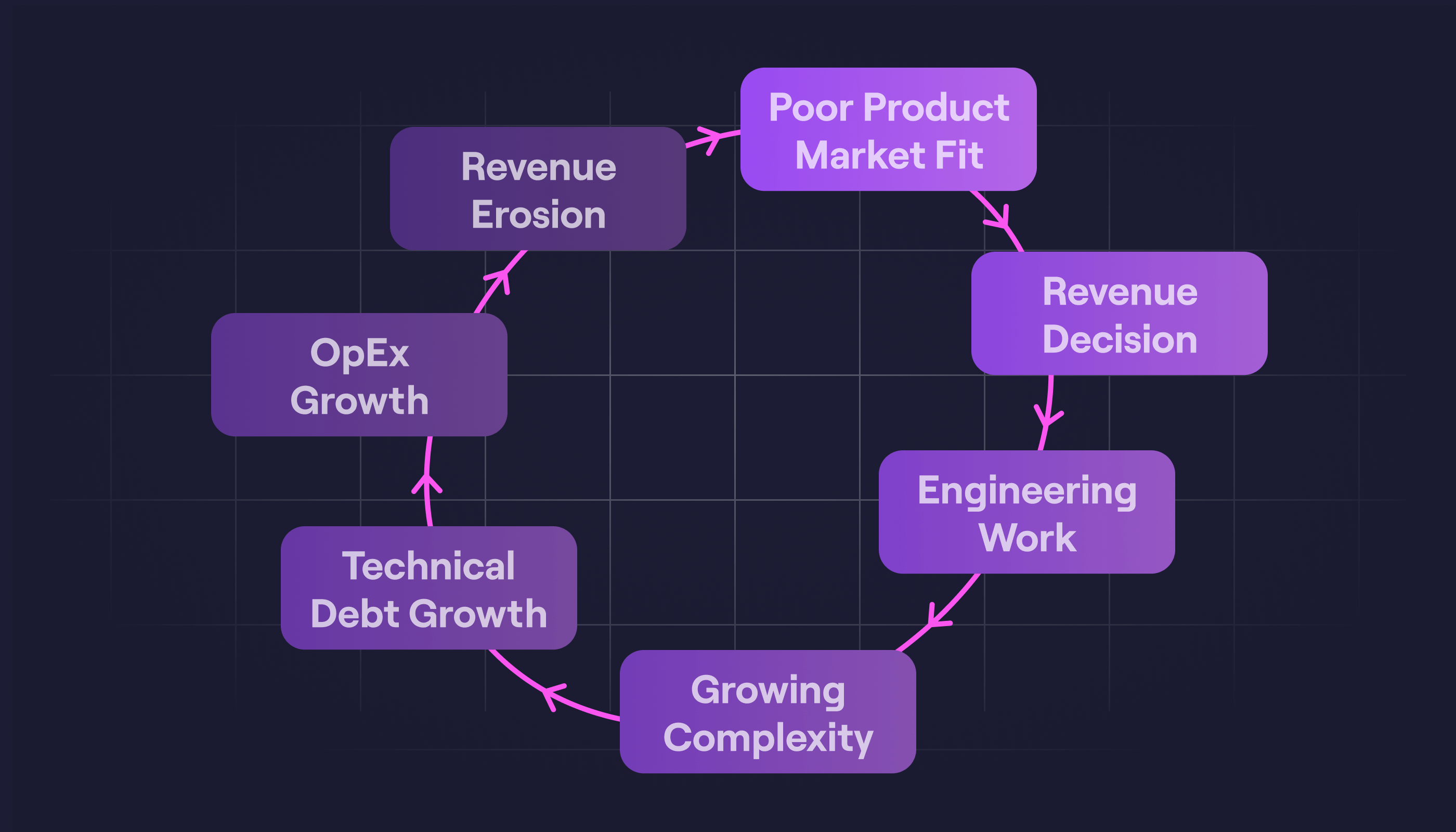
This dynamic forms a reinforcing loop:
- Revenue pressure increases bespoke commitments
- Each commitment introduces architectural variation and support overhead
- Variation slows delivery and raises the cost of change
- Reduced capacity creates more revenue pressure to "close the gap"
- New revenue brings further bespoke commitments, resetting the cycle
In my experience, once architectural complexity exceeds organisational capacity, your system enters structural decline. You start to see elevated OpEx, extended lead times, and reduced reliability in your architecture.
John Cutler illustrates this dynamic well in his widely shared observation that teams that underinvest in managing complexity eventually find their capacity consumed by unplanned work. When organisations focus disproportionately on new capability demand, the system becomes structurally overloaded, and the operational burden grows faster than engineering can absorb.
Why refactoring stalls
This brings us to refactoring, which is typically the mechanism you rely on to restore order, though it tends to fail to achieve that when commercial demand reintroduces complexity faster than teams can remove or simplify it. Even disciplined, well-executed refactors cannot deliver lasting benefit if a steady stream of bespoke commitments continues unchecked. Under these conditions, the improvements you make offer only temporary stabilisation rather than meaningful system-level recovery.
Contrary to popular belief, tech debt rarely starts in the codebase itself, rather it originates in the incentives that prioritise short-term revenue over architectural integrity. No amount of technical excellence can offset a commercial strategy that repeatedly generates divergent outcomes.
Breaking the cycle
Experience tells us that there is no big bang rewrite capable of rescuing an architecture that has evolved this way. Such rewrites rarely succeed (Netscape’s failed rewrite being a well-known example). The sustainable path forward is disciplined focus, transparency, and rebalanced investment.
1. Define the strategic core
You should identify the capabilities and products that truly represent the future architecture. Align teams, metrics, and investment around that core. Everything else either enables it or moves toward retirement. Frameworks such as the Product Operating Model and Team Topologies help institutionalise this alignment.
2. Make cost to serve visible
Every pound of revenue carries infrastructure, support, and human effort. When you expose these costs to the broader team, you create space for rational trade-offs. Cost to serve transparency helps engineering show precisely where targeted refactors, platform consolidation, or migration sequencing will reduce OpEx and restore capacity.
3. Fund value flywheels
Invest in platforms, shared components, and reusable capabilities that compound value. Each adoption cycle should reduce marginal cost and accelerate future delivery, turning your day-to-day work into strategic momentum.
Evolving while moving
Transformation begins from within constraints you already live with: full workloads, tight coupling, and customers reliant on today’s architecture. Under these conditions, progress must be incremental and demonstrable. Evolutionary techniques such as strangler fig migrations, microfrontends, and platform consolidation are most effective when bounded contexts can be clearly separated and responsibilities incrementally shifted.
Each visible improvement builds both political capital and technical confidence for you, enabling the next step without halting delivery.
From code quality to system health
Good architectural health is often confused with clean code, modularity, loose coupling, and well-defined patterns. And whilst engineering excellence is essential for operating at pace, it represents only a small part of what your software development lifecycle needs to be truly effective.
Sustainable architectural health depends on how well revenue goals, product needs, and technology strategy align. When you keep these three connected, technical debt grows more slowly, operational risk decreases, and teams can improve the product more easily. When they fall out of sync, even well-architected systems struggle, and delivery performance starts to decline as complexity increases.
Revenue debt is often the first clear sign that things are out of alignment. You see it when architectural choices prioritise protecting existing income instead of supporting future growth, creating short-term benefits at the cost of long-term flexibility. In this situation, refactoring alone cannot restore resilience because the incentives driving the work continue to produce the same fragmented outcomes.
The engineering leader's responsibility
You might see your work in terms of people, engineering practice, tooling, and improvement. But the more important responsibility is shaping an environment where systems of people and technology can change predictably, safely, and with minimal friction.
This responsibility includes:
- Explaining the economic impact of complexity in ways that commercial and operational leaders can act on
- Bringing data-driven analysis into strategic choices so decisions are based on evidence, not preference
- Protecting the organisation from architectural decisions that meet short-term revenue needs but undermine long-term scalability
You must act as both architect and translator, linking day-to-day technical realities to commercial decisions.
